Archivo:RAG schema.svg

Tamaño de esta previsualización PNG del archivo SVG: 800 × 324 píxeles. Otras resoluciones: 320 × 130 píxeles · 640 × 259 píxeles · 1024 × 415 píxeles · 1280 × 519 píxeles · 2560 × 1037 píxeles · 4249 × 1722 píxeles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ver la imagen en su resolución original ((Imagen SVG, nominalmente 4249 × 1722 pixels, tamaño de archivo: 76 kB))
{kind=link}
Resumen
| Descripción |
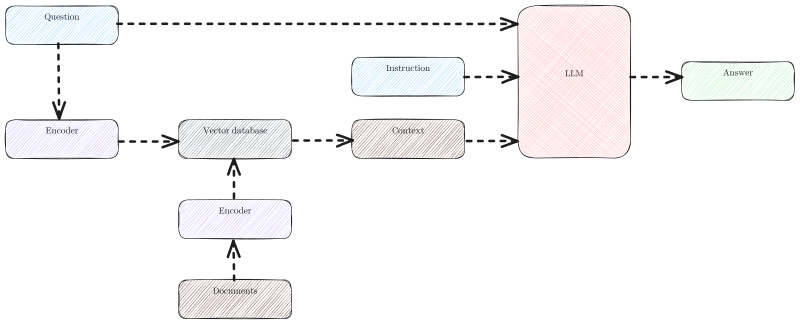
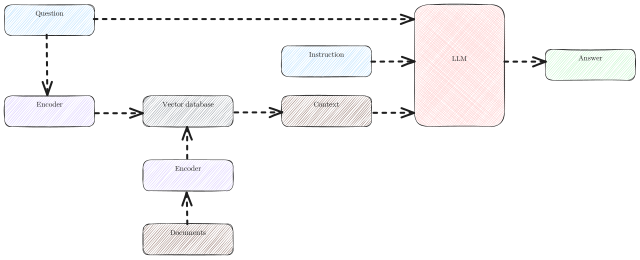
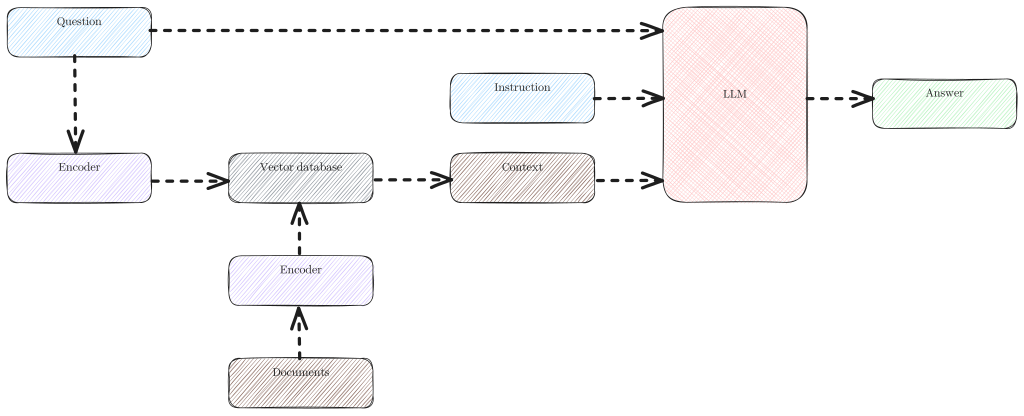
English: Diagram illustrating the two-phase process for document retrieval using dense embeddings.
Indexing Phase:
Documents are transformed into vector representations using dense embeddings.
These vectors are stored in a vector database.
Inference Phase:
The posed question is converted into a query vector using the same embedding technique.
The vector database retrieves the top four most relevant articles by computing the cosine distance between the query vector and stored document vectors.
The content of the selected articles is introduced to the Large Language Model (LLM) as context, together with the original question.
The LLM is then instructed to formulate an answer.
This process ensures efficient and relevant document retrieval based on the semantic content of queries.Polski: Diagram ilustrujący dwuetapowy proces wyszukiwania dokumentów przy użyciu gęstych osadzeń.
Faza indeksowania:
Dokumenty są przekształcane w reprezentacje wektorowe przy użyciu gęstych osadzeń.
Te wektory są przechowywane w wektorowej bazie danych.
Faza wnioskowania:
Zadane pytanie jest konwertowane na wektor zapytania przy użyciu tej samej techniki osadzania.
Wektorowa baza danych wyszukuje cztery najbardziej odpowiednie artykuły, obliczając odległość kosinusową między wektorem zapytania a przechowywanymi wektorami dokumentów.
Treść wybranych artykułów jest wprowadzana do Dużego Modelu Językowego (LLM) jako kontekst, wraz z oryginalnym pytaniem.
Następnie instruuje się LLM, aby sformułował odpowiedź.
Ten proces gwarantuje efektywne i trafne wyszukiwanie dokumentów na podstawie semantycznej zawartości zapytań.Українська: Діаграма, яка показує двоетапний процес пошуку документів з використанням щільних вкладень.
Етап індексування:
Документи перетворюють на векторні подання з використанням щільних вкладень.
Ці вектори зберігають у векторній базі даних.
Етап висновування:
Задане питання перетворюють на вектор запиту з використання того же щільного подання.
Векторна база даних знаходить чотири найвідповідніші позиції, обчислюючи косинусну відстань між вектором запиту та векторами збережених документів.
Вміст обраних позицій пропонується Великій Мовній Моделі (ВММ) як контекст, разом із первинним запитанням.
ВММ відтак кажуть сформулювати відповідь.
Цей процес забезпечує ефективний та доречний пошук документів на основі семантичного вмісту запитів. |
| Fecha | |
| Fuente | Trabajo propio |
| Autor | Gknor |
| SVG desarrollo | El código fuente de esta imagen SVG es válido. Este gráfico vectorial fue creado con una desconocida SVG herramienta This file is translated using SVG switch elements: all translations are stored in the same file. |
{kind=link}
Licencia
Yo, el titular de los derechos de autor de esta obra, la publico en los términos de la siguiente licencia:
Este archivo está disponible bajo la licencia Creative Commons Attribution-Share Alike 4.0 International.
- Eres libre:
- de compartir – de copiar, distribuir y transmitir el trabajo
- de remezclar – de adaptar el trabajo
- Bajo las siguientes condiciones:
- atribución – Debes otorgar el crédito correspondiente, proporcionar un enlace a la licencia e indicar si realizaste algún cambio. Puedes hacerlo de cualquier manera razonable pero no de manera que sugiera que el licenciante te respalda a ti o al uso que hagas del trabajo.
- compartir igual – En caso de mezclar, transformar o modificar este trabajo, deberás distribuir el trabajo resultante bajo la misma licencia o una compatible como el original.
Historial del archivo
Haz clic sobre una fecha y hora para ver el archivo tal como apareció en ese momento.
| Fecha y hora | Miniatura | Dimensiones | Usuario | Comentario | |
|---|---|---|---|---|---|
| actual | 10:37 2 ene 2024 | 4249 × 1722 (76 kB) | Olexa Riznyk | File uploaded using svgtranslate tool (https://svgtranslate.toolforge.org/). Added translation for uk. | |
| 13:49 24 oct 2023 | 4249 × 1722 (72 kB) | Gknor | Uploaded own work with UploadWizard |
{kind=link}
Usos del archivo
La siguiente página usa este archivo:
Uso global del archivo
Las wikis siguientes utilizan este archivo:
- Uso en bs.wiki.x.io
- Uso en en.wiki.x.io
- Uso en fa.wiki.x.io
- Uso en pl.wiki.x.io
- Uso en uk.wiki.x.io
- Uso en vi.wiki.x.io
{kind=link}